1. 客服agent
客户问题种类: 事实类问题、诊断类问题、模糊类问题、其他问题等
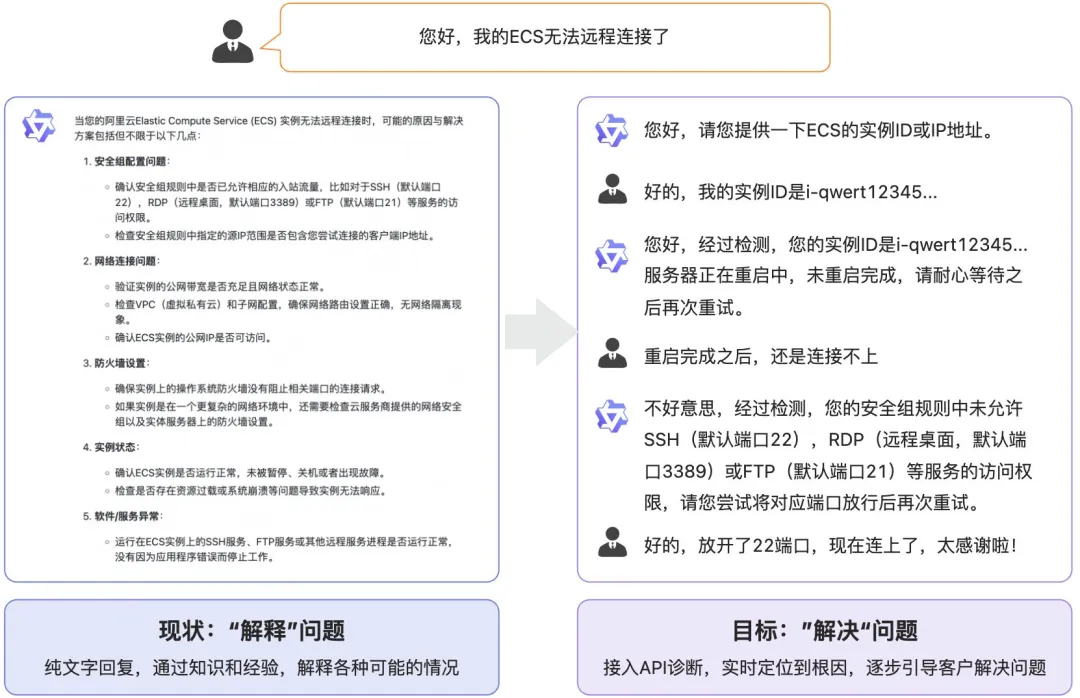
诊断类问题
解释问题 VS 解决问题
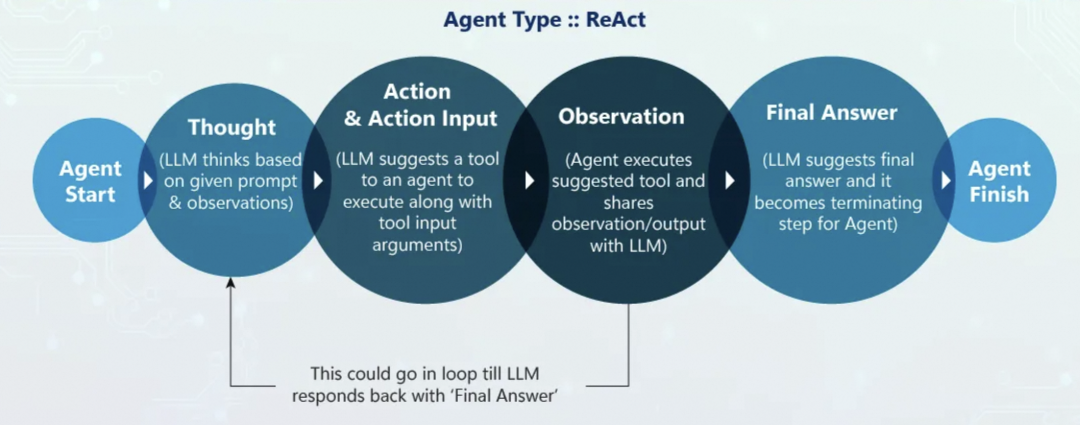
React Agent
从Agent的最开始,LLM先思考(Thought),然后触发动作(Action)和输入(Action Input),之后执行并观察工具执行结果(Observation),如果观察的效果不满足需求,会重回到思考阶段,最后生成最终回答(Final Answer)
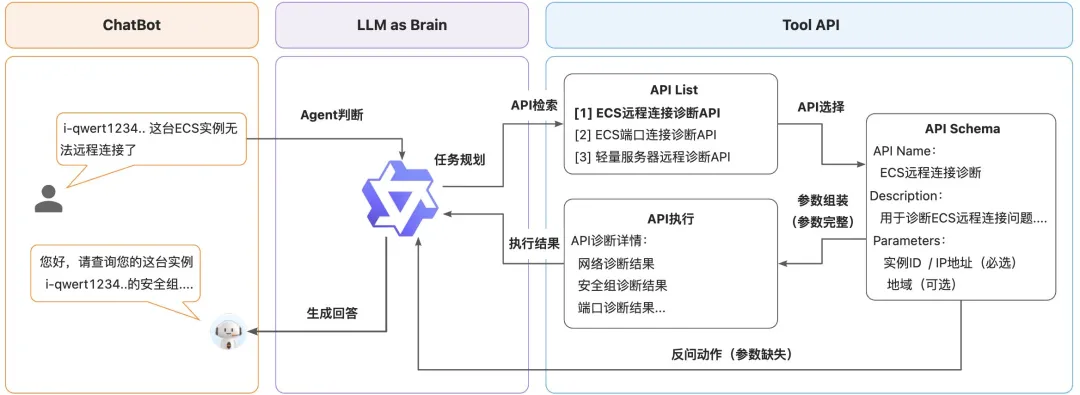
选择API、反问、提取入参、执行API的准确度
“问题识别” -> “查询SOP工具” -> “反问客户、获取信息” -> “根据信息查询工具” -> “查询到工具执行结果” -> “根据执行结果来回复客户” -> “客户继续沟通” -> … -> “解决问题”
TEXT
用户提问 -> 判断意图 -> 模糊 -> 追问
-> 清楚 - 需要进入agent? -> api检索 -> api选择 -> 参数判断 -> 参数组装 -> 动作执行 -> 观察结果 -> 生成答案
-> 不足 -> 追问问题与优化
在实际业务落地的情况下,需要考虑几个因素:执行效果、整体耗时、大模型生成成本、API调用成本等等诸多因素,如果效果好,但是耗时太久,或者大模型的生成成本(token、qps)、API的调用成本(qps)等都太高,那么也未必有好的用户体验。
- 多步调用耗时,将api做到开箱即用,支持多种传参方式,减少对用户的询问。
- 慢api作异步处理,前端显示卡片展示进度。
- 构造高质量的训练数据集来对模型进行Finetune训练,让大模型在选择API、反问、提取入参、执行API的准确度上都尽可能的高
2. why agent?
agent: 让大模型“代理/模拟”「人」的行为,使用某些“工具/功能”来完成某些“任务”的能力。
Agent = 大模型(LLM)+ 规划(Planning)+ 记忆(Memory)+ 工具使用(Tool Use)
- 降低应用开发门槛
- 简化流程复杂度
- 交互方式多样性
- 协同完成复杂任务
挑战
速度慢
模型层面:
KV cache, 模型参数裁剪,模型蒸馏, 量化技术
工程层面:
大文本、大文档的读取,可以使用预处理的方式将其切块,prompt压缩
幻觉
引导Prompt的规范化书写,基于慢思考的System2,GraphRAG,Agent预编译能力
OpenManus
- 解析目标 -> 生成初始 Todo List。
- 进入死循环(While < maxSteps): 只要 Todo List 没清空,就一直循环。
- 取出一个任务 -> 思考(Reasoning) -> 选择工具(Action) -> 在沙盒执行 -> 观察结果(Observation)。
- 根据结果 -> 更新上下文 -> 动态修改或划掉 Todo List -> 进入下一次循环。
- 所有任务完成 -> 汇总输出结果。
任务规划 -> 任务执行 -> 任务反思
将任务拆分为粗粒度子任务,依次执行每个子任务,执行子任务时进一步拆分细粒度任务,执行出错进行调整,执行过程中生成todo list

构建高可用agent
关于agent的一些争论
智能体 vs 代理: Agent一定是要“智能”的吗?这意味着Agent是否必须是由LLM驱动?满足“代理”能力的程序、代码块是否可以叫Agent?
自主规划 vs 工作流: Agent一定是要能“自主规划”吗?预定义好的规划(如Workflow),是否能被叫做Agent?
函数调用 vs 角色扮演: Agent一定要实现函数调用吗?如果只是通过Prompt完成一段指令,是否被称作Agent?Agent一定要有“人”的属性吗?角色扮演类的LLM,是否属于Agent?
落地过程中的挑战
- 运行效果不稳定 提示词不能稳定运行,大模型不能严格按照提示词的指示执行
提示词模板,AI辅助做提示词生成和调优
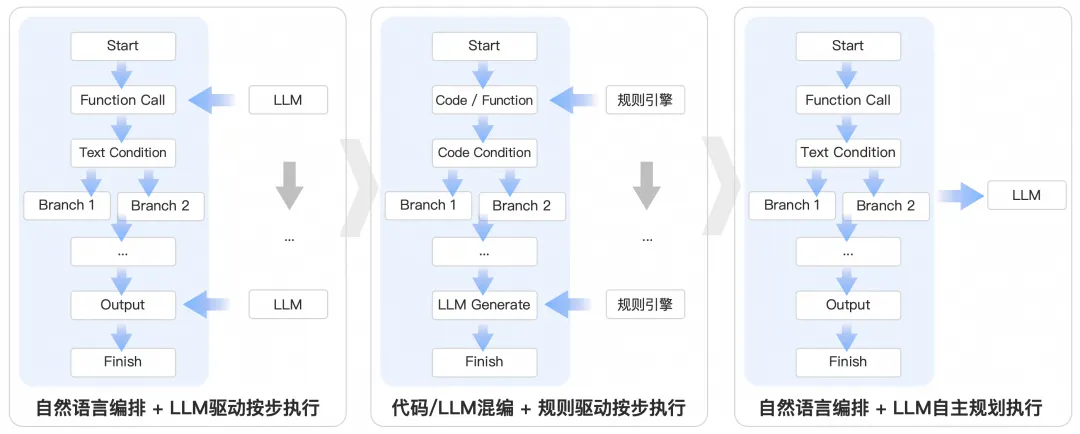
- 规划如何平衡 自主规划和workflow如何平衡,太自主会脱离预期乱执行,硬编码workflow会花费大量人力成本。
Agentic RAG,大模型自主生成搜索的query,进行搜索
- 领域信息集成 如何将领域信息或者领域知识注入到大模型里面
Prompt中动态领域: 动态引入领域先验知识,通过类似RAG的方式根据场景动态搜索和匹配加载领域的知识或者业务经验 引入外部技能: 通过调用领域工具、知识库、文档等,让LLM有更多方式自主选择获取领域数据 领域大模型训练: 通过模型预训练、后训练等多阶段的训练
- Agent的响应速度 运行性能和推理效果是呈反比的关系,大参数的模型效果不错,但速度慢,尤其是带有思考的推理模型。小参数的模型速度快,但运行Agent的效果一般,经常不稳定。
代码参数预转换:尽量减少Agent中大模型参与的比例,比如使用流程预编译好的Workflow,将非必要的LLM模块转换为代码或脚本语言 各种推理加速方式:通过各种加速推理的优化方法来提升模型的运行效率,比如模型量化(Int4、int8等)、优化KV Cache、使用各种加速框架(如FlashAttention、vLLM等)、更换高性能GPU等 降低模型参数量:用大参数量的LLM作为教师模型去蒸馏小参数量的LLM
构建
从使用提示词开始构建原型,到Workflow的构造、Multi-Agent架构设计、模型的训练和调优。
如何让Agent更符合预期(基于上下文工程和多智能体)经验
经验一:清晰化你的预期
核心原则:避免模糊预期,给到足够清晰的预期,让大模型理解起来没有任何的歧义和困惑。
任务要求task,输出格式format,风格语气style
经验二:上下文精准投喂
核心原则:“给其所需,去其所扰”。模型需要且关心的信息,一定要给到;模型不需要且不相关的干扰信息,一定要想办法剔除。
经验三:身份和历史执行清晰化
核心原则:模型需要明确知道有几方的身份,需要知道自己做过哪些事情,当前执行到哪个阶段。
经验四:善用结构化形式表达逻辑
核心原则:相对复杂的流程、逻辑,可以优先考虑形式化、结构化方式表达,不要只用自然语言。
用json等结构化的提示词
经验五:尝试自定义工具协议
核心原则:如果你的领域任务相对独特且对稳定性要求较高,自定义工具协议和指令是值得尝试的。
经验六:Few-Shot要合理使用
核心原则:灵活性强的场景慎用Few-Shot,特定任务中建议用多样化的Few-Shot。
给出示例,llm模仿示例回复。
经验七:保持上下文的“苗条”
核心原则:在不损失性能的前提下,尽可能对上下文进行“瘦身”。
经验八:使用记忆管理来避免模型遗忘
核心原则:重点信息多次增强提示,上下文压缩减少历史对话轮次,外部存储帮助实时唤起更久的记忆。
经验九: 使用Multi-Agent来平衡可控性与灵活性
核心原则:Workflow提升可控性,LLM自主决策提升灵活性,好的Multi-Agent设计既可控又能灵活。
经验十: 只有HITL才能做出更好的Agent
核心原则:只有坚持人在回路(HITL),深入业务场景中,才能做出好的Agent。
想要做好Agent,必须要先知道“人”是怎么做的,让agent学着人做。
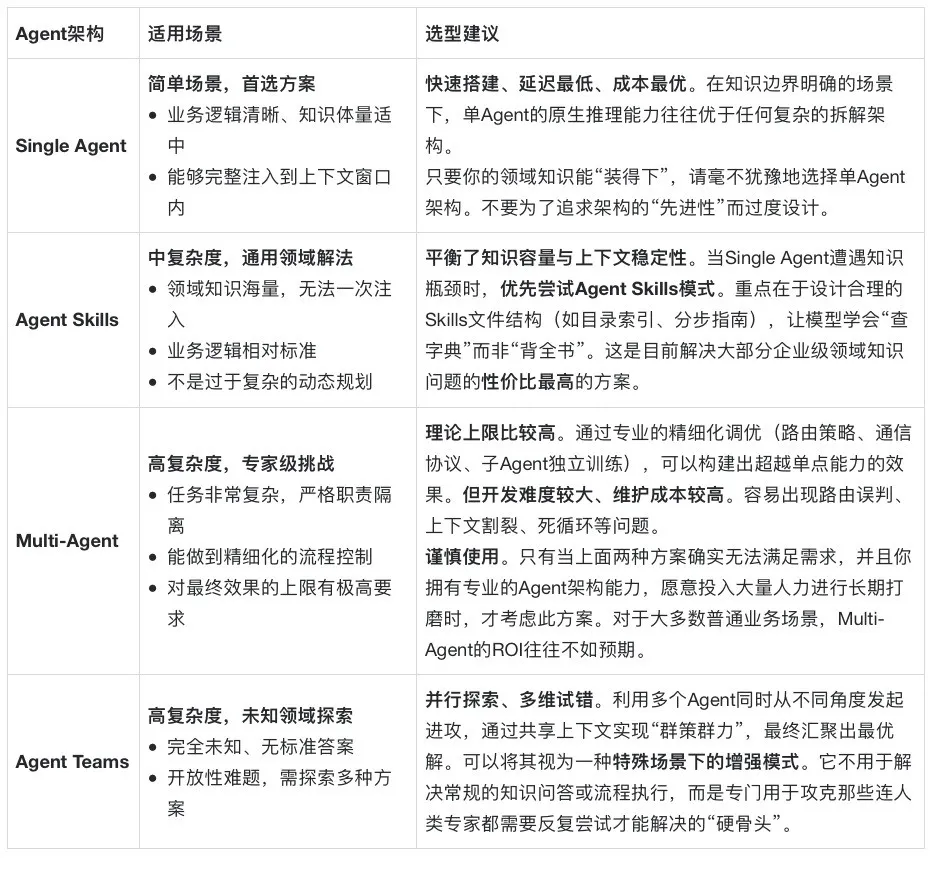
Agent/Skills/Teams 架构演进及技术选型
基础大模型无法完美内化“领域知识”和高效复用“长期记忆”的背景下,不断尝试“外挂”出这些能力的。本质上就是大家对大模型如何更好的注入领域知识和记忆管理这两方面的需求,不断促进了Agent架构的演化。
Single Sgent
Multi Agent
解决领域知识的隔离与高效注入问题
Skills
用文件系统的结构化能力替代了复杂的网络通信协议,用渐进式的信息披露替代了暴力的全量注入。
Agent Teams
探索高度不确定性的决策难题。
指导性结论
- 模型越强效果越好,但并非Agent越多效果就越好
- 尽量降低沟通成本和通信带宽
- 单Agent的45%阈值法则
- 错误放大效应
- 场景决定架构:没有万能钥匙
选型