MySQL 技术要点
一、MySQL 架构
MySQL 采用分层架构设计,主要分为 Server 层 和 存储引擎层。
1.1 Server 层
| 组件 | 职责 |
|---|---|
| 连接器 | 管理客户端连接、身份认证、权限校验 |
| 分析器 | 词法分析(识别关键字、表名、列名)、语法分析(构建语法树) |
| 优化器 | 生成执行计划、选择最优索引、决定 JOIN 顺序 |
| 执行器 | 调用存储引擎 API 执行查询,返回结果集 |
1.2 存储引擎层
MySQL 支持插件式存储引擎,常用引擎对比:
| 引擎 | 事务支持 | 锁粒度 | 适用场景 |
|---|---|---|---|
| InnoDB | ✓ | 行锁 | OLTP、高并发读写 |
| MyISAM | ✗ | 表锁 | 只读或读多写少 |
| Memory | ✗ | 表锁 | 临时表、缓存 |
InnoDB architecture
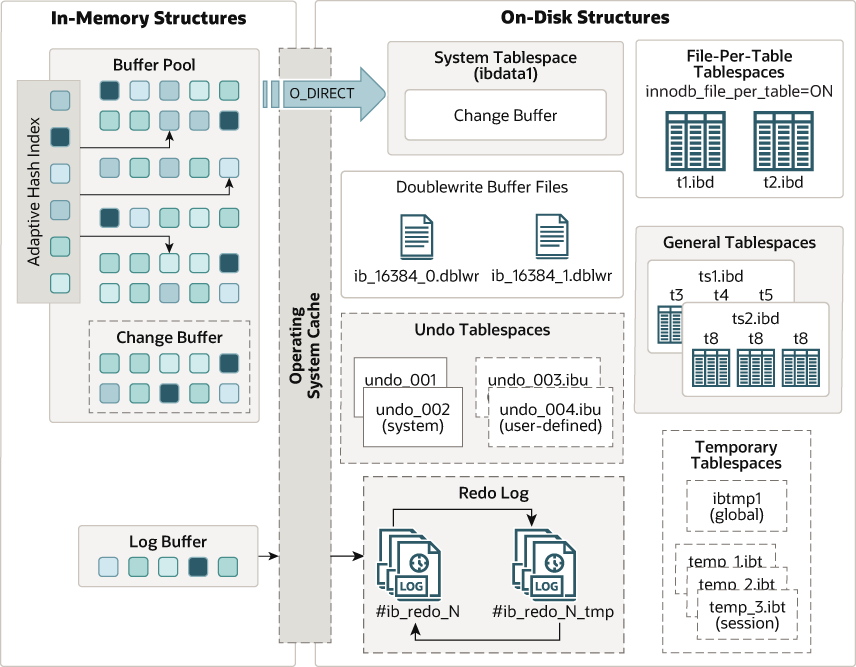
二、索引机制
2.1 索引数据结构
| 类型 | 特点 | 适用场景 |
|---|---|---|
| B+ Tree | 有序、支持范围查询、树高稳定 | 主键索引、普通索引 |
| Hash | O(1) 查找、不支持范围查询 | 等值查询(Memory 引擎) |
| Full-Text | 倒排索引、支持自然语言搜索 | 全文检索 |
2.2 索引分类
按物理存储:
- 聚簇索引(Clustered Index):叶子节点存储完整行数据,InnoDB 主键索引即聚簇索引
- 二级索引(Secondary Index):叶子节点存储主键值,查询需回表
按字段特性:
- 主键索引:唯一且非空,一张表只能有一个
- 唯一索引:字段值唯一,允许 NULL
- 普通索引:无唯一性约束
- 前缀索引:对字符串前 N 个字符建立索引,节省空间
按字段数量:
- 单列索引:单个字段
- 联合索引:多个字段组合,遵循最左前缀原则
三、事务
3.1 ACID 特性
| 特性 | 含义 | 实现机制 |
|---|---|---|
| Atomicity(原子性) | 事务要么全部成功,要么全部回滚 | Undo Log |
| Consistency(一致性) | 事务前后数据库状态一致 | 由其他三个特性共同保证 |
| Isolation(隔离性) | 并发事务互不干扰 | MVCC + 锁 |
| Durability(持久性) | 已提交事务永久生效 | Redo Log |
3.2 隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read Uncommitted | ✓ | ✓ | ✓ |
| Read Committed | ✗ | ✓ | ✓ |
| Repeatable Read(默认) | ✗ | ✗ | ✓* |
| Serializable | ✗ | ✗ | ✗ |
*InnoDB 在 RR 级别下通过 Next-Key Lock 解决了大部分幻读问题。
3.3 MVCC(多版本并发控制)
MVCC 通过为每行数据维护多个版本,实现非阻塞的一致性读:
- 隐藏列:
DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID - Read View:记录活跃事务列表,决定数据可见性(RC 级别每次读取时创建,RR 级别仅首次读取时创建)
- 版本链:通过 Undo Log 构建历史版本链表
3.4 当前读与快照读
-- 快照读:读取 MVCC 快照版本
SELECT * FROM t WHERE id = 1;
-- 当前读:读取最新版本并加锁
SELECT * FROM t WHERE id = 1 FOR UPDATE; -- 排他锁
SELECT * FROM t WHERE id = 1 LOCK IN SHARE MODE; -- 共享锁
四、锁机制
4.1 锁分类
锁
├── 全局锁
│ └── FTWRL (Flush Tables With Read Lock)
├── 表级锁
│ ├── 表锁 (LOCK TABLES)
│ ├── 元数据锁 (MDL)
│ └── 意向锁 (IS/IX)
└── 行级锁 (InnoDB)
├── 记录锁 (Record Lock)
├── 间隙锁 (Gap Lock)
└── 临键锁 (Next-Key Lock)
4.2 行锁加锁规则
InnoDB 行锁的加锁规则:
- 加锁基本单位是 Next-Key Lock(前开后闭区间)
- 只对访问到的对象加锁
- 唯一索引等值查询命中时,Next-Key Lock 退化为行锁
- 等值查询向右遍历到不满足条件的记录时,Next-Key Lock 退化为间隙锁
4.3 幻读与间隙锁
幻读定义:同一事务中,后一次查询看到了前一次查询没看到的行(专指新插入的行,不包括更新和删除)。
解决方案:间隙锁 + 行锁 = Next-Key Lock
例如,对表 t(主键值为 0, 5, 10, 15, 20, 25)执行 SELECT * FROM t FOR UPDATE,会形成以下 Next-Key Lock:
(-∞, 0],(0, 5],(5, 10],(10, 15],(15, 20],(20, 25],(25, +supremum]
注意:
LOCK IN SHARE MODE仅锁覆盖索引,而FOR UPDATE会同时锁定主键索引上满足条件的行。
五、日志系统
5.1 日志类型
| 日志 | 作用 | 所属层 |
|---|---|---|
| Redo Log | 保证持久性,崩溃恢复 | InnoDB 引擎层 |
| Undo Log | 保证原子性,支持 MVCC | InnoDB 引擎层 |
| Binlog | 主从复制、数据备份 | Server 层 |
| Relay Log | 从库接收主库 Binlog 的中继日志 | Server 层 |
5.2 Binlog 格式
| 格式 | 特点 |
|---|---|
| Statement | 记录 SQL 语句,日志量小,但可能导致主从不一致 |
| Row | 记录行变更,日志量大,主从一致性好 |
| Mixed | 自动选择,默认 Statement,特殊情况用 Row |
5.3 两阶段提交
为保证 Redo Log 和 Binlog 数据一致性,采用两阶段提交:
- Prepare 阶段:Redo Log 写入并标记为 prepare 状态
- Commit 阶段:Binlog 写入 → Redo Log 标记为 commit
组提交优化:多个事务的日志合并写入,减少磁盘 I/O。
5.4 Doublewrite
InnoDB 使用 Doublewrite Buffer 解决部分页写入(Partial Page Write)问题:
- 先将脏页写入 Doublewrite Buffer(顺序写)
- 再将脏页写入数据文件(随机写)
- 崩溃恢复时,若数据页损坏,可从 Doublewrite Buffer 恢复
六、主从复制
6.1 复制流程
主库:事务提交 → 写 Binlog
↓
从库 I/O 线程:读取主库 Binlog → 写入 Relay Log
↓
从库 SQL 线程:重放 Relay Log → 更新数据
6.2 主备延迟原因
- 从库机器性能较差
- 从库承担过多查询压力
- 大事务执行时间长
- 网络延迟
6.3 处理过期读
| 方案 | 实现复杂度 | 一致性 |
|---|---|---|
| 强制走主库 | 低 | 强 |
| Sleep 延迟 | 低 | 弱 |
| 判断主备无延迟 | 中 | 较强 |
| Semi-Sync 半同步 | 中 | 强 |
| 等主库位点 | 高 | 强 |
| 等 GTID | 高 | 强 |
七、性能优化
7.1 执行计划分析(EXPLAIN)
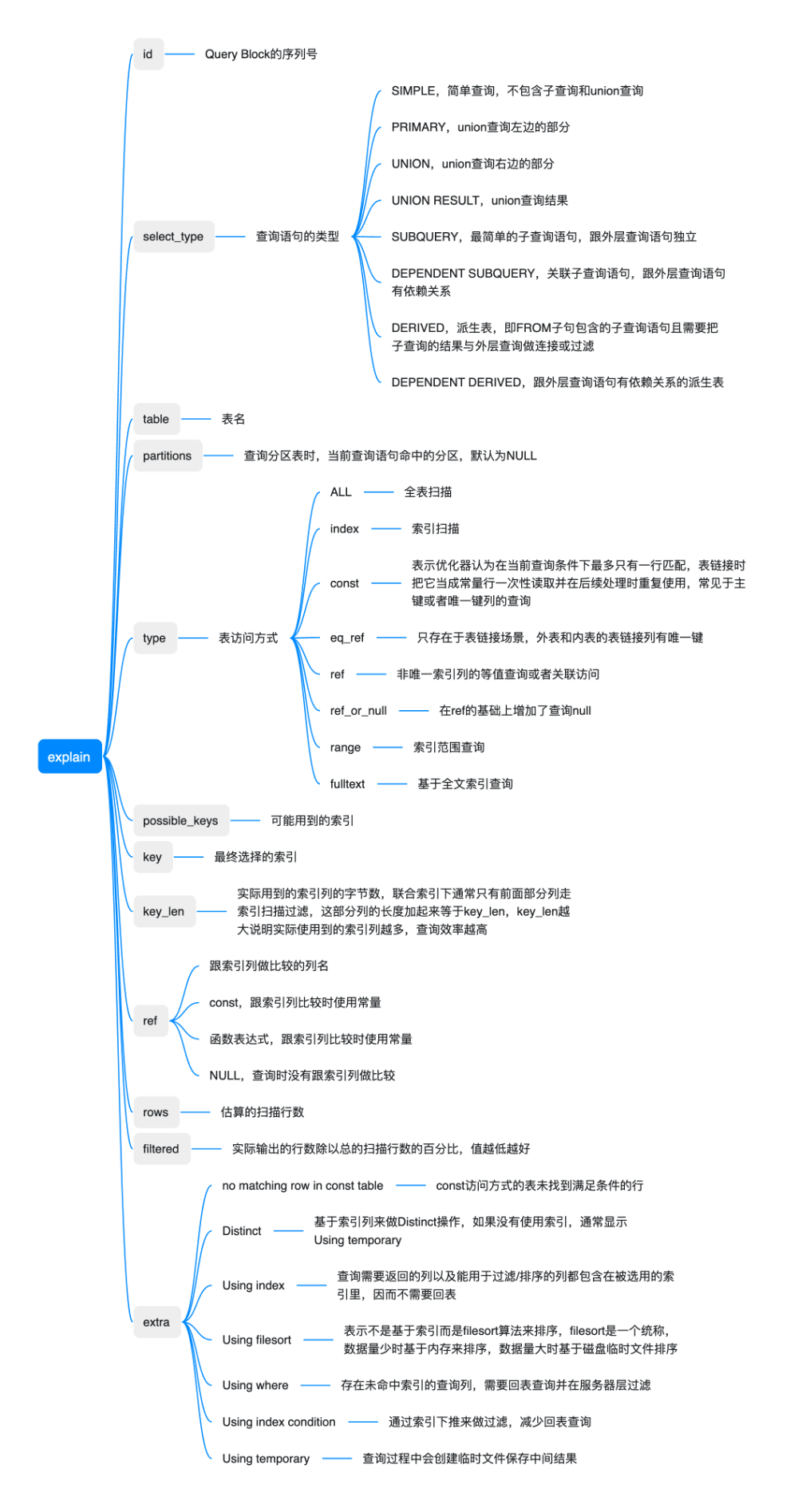
7.2 慢查询诊断
-- 查看当前执行的 SQL 状态
SHOW PROCESSLIST;
-- 查看行锁等待(MySQL 8.0+)
SELECT * FROM sys.innodb_lock_waits;
查询长时间不返回的原因:
- 等待 MDL(Metadata Lock)
- 等待 Flush
- 等待行锁
查询慢的原因:
- 快照读需遍历长版本链
- 扫描行数过多
- 索引选择不当
- 客户端接收慢(MySQL 边读边发,导致
net_buffer阻塞)
7.3 索引优化
普通索引 vs 唯一索引:
- 普通索引可利用 Change Buffer 优化写入,数据不在内存时直接写入 Change Buffer
- 唯一索引必须读取数据页判断唯一性,无法使用 Change Buffer
优化器选错索引的处理:
-- 重新统计索引信息
ANALYZE TABLE t;
-- 强制使用指定索引
SELECT * FROM t FORCE INDEX(idx_name) WHERE name = 'test';
7.4 性能抖动原因
- Redo Log 写满,触发 Checkpoint 刷脏页
- Buffer Pool 满,淘汰脏页需先刷盘
- 后台线程定期刷脏页
Buffer Pool LRU 优化
InnoDB 采用改进的 LRU 算法(Young 区:Old 区 = 5:3)防止缓存污染:
- 新数据先放入 Old 区域
- 在 Old 区域停留超过
innodb_old_blocks_time后再次访问,才移入 Young 区域 - 防止全表扫描等操作将热点数据挤出缓存
7.5 JOIN 算法
| 算法 | 条件 | 特点 |
|---|---|---|
| Index Nested-Loop Join | 被驱动表连接字段有索引 | 性能好,复杂度 O(N×logM) |
| Block Nested-Loop Join | 无索引,使用 Join Buffer | MySQL 8.0.18 前使用 |
| Hash Join | MySQL 8.0.18+ 无索引时自动使用 | 替代 BNL,性能更好 |
- MRR:将随机 I/O 转为顺序 I/O,先读取索引排序后再回表
- BKA:基于 MRR,批量将驱动表数据传递给被驱动表查询
7.6 ORDER BY 优化
最优情况:利用索引有序性,EXPLAIN 不出现 Using filesort。
filesort 算法(无索引时):
| 算法 | 特点 |
|---|---|
| 全字段排序 | 所有字段放入 Sort Buffer,排序后直接返回 |
| Rowid 排序 | 仅排序字段+主键,排序后回表,适用于宽表 |
MySQL 根据
max_length_for_sort_data自动选择:行宽超过该值时使用 Rowid 排序。
7.7 外部排序
当 Sort Buffer 不足时,MySQL 使用外部排序:
- 归并排序:分批排序写入临时文件,最后多路归并
- 优先队列:
ORDER BY ... LIMIT N场景,维护 N 个元素的堆,避免全量排序
八、常见问题与解决方案
8.1 删除数据不释放空间
-- DELETE 仅标记删除,空间不会立即释放
DELETE FROM t WHERE create_time < '2024-01-01';
-- 重建表释放空间
ALTER TABLE t ENGINE = InnoDB;
8.2 COUNT 性能
性能从低到高:count(字段) < count(id) < count(1) ≈ count(*)
count(*)经过优化器特殊优化,推荐使用。
8.3 临时表
触发场景:UNION 去重、GROUP BY 无索引、复杂子查询。
8.4 分区表
分区表在引擎层分区,对业务透明。优势:ALTER TABLE t DROP PARTITION p_2023 比 DELETE 更快。
适用场景:按时间分区的日志表、历史数据表。
8.5 数据迁移
| 方式 | 特点 |
|---|---|
| 物理拷贝 | 速度快,仅限同引擎、同版本 |
| mysqldump | 通用,不支持复杂 WHERE |
| SELECT INTO OUTFILE | 支持所有 SQL,仅导出单表 |
参考资料:MySQL 实战 45 讲、《高性能 MySQL》、从一条慢SQL说起:交易订单表如何做索引优化