前言
主从复制可以显著提升系统的读能力,但复制滞后会直接破坏多端同步体验。 本文聚焦三个最常见的一致性问题:读自己写、单调读、前缀一致读,以及在即时通讯场景中的对应治理手段。
读自己的写
读自己写失效:客户端提交了写入,但随后的读取请求被路由到了尚未完成同步的从节点,导致客户端读不到自己刚刚写入的数据。
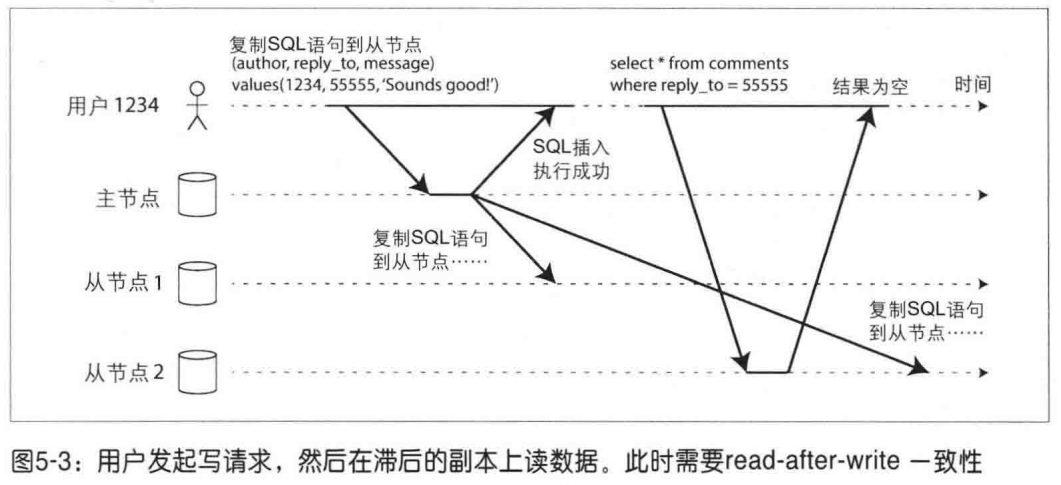
- 用户读自己写数据,强制走主节点。如果大部分数据都修改,会给主库造成巨大压力
- 用户记录最近更新时间戳,可以是逻辑时间和系统时钟(时钟不可靠)。多设备不适用,并不知道记录的时间戳。
单调读
单调读失效:用户的多次读取请求打到了同步进度不一致的多个副本上,导致用户先看到了较新的数据,随后又看到了较旧的数据,出现了“时光倒流”。
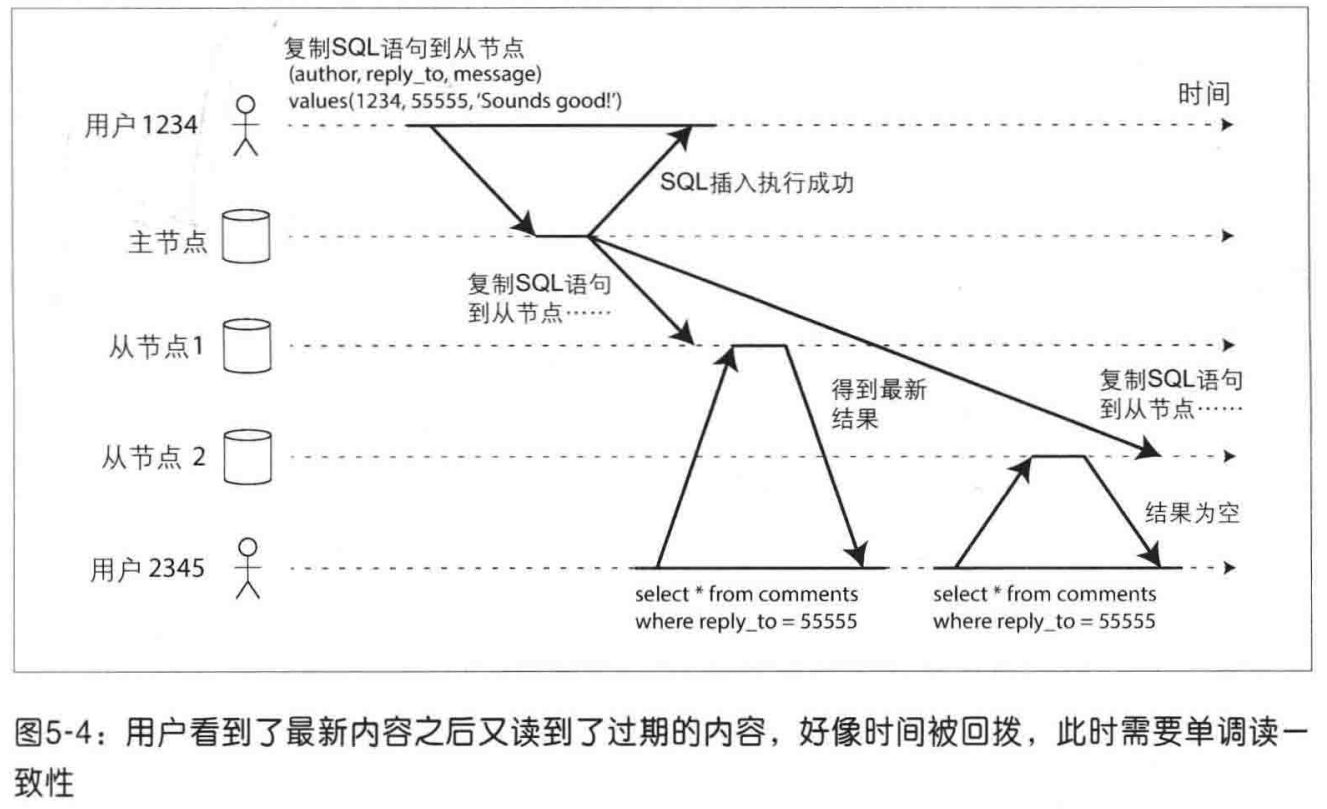
- 始终从同一副本读取,例如基于用户id哈希。但是如果副本失效,必须重新路由到另一个副本
前缀一致读
前缀/因果一致性失效:具有因果关系(先后顺序)的写入,由于底层分布式组件的处理速率不一致,导致在第三方的视角中,事件发生的顺序被颠倒。
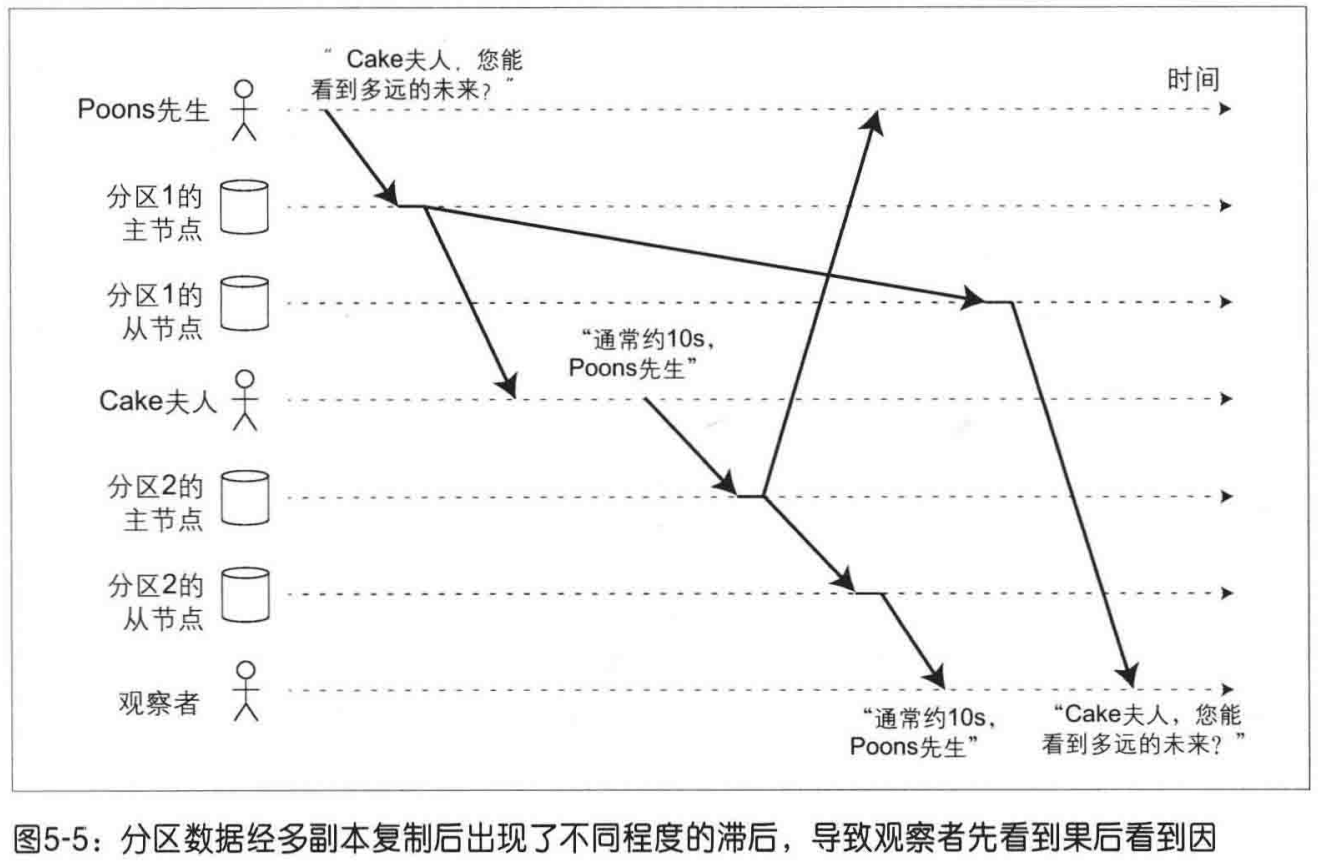
- 将具有因果顺序的都交由一个分区处理。效率低
即时通讯场景下的主从滞后问题
读自己写失效(Read-Your-Writes Anomaly)
- 多端同步丢失: 用户在手机端发了一条消息,成功写入服务端主库。用户立刻打开电脑端(PC 版)查看,PC 端的拉取请求恰好打到了一个由于网络抖动而延迟了 500 毫秒的 MySQL 从库。结果 PC 端界面上一片空白,用户以为消息没发出去。
- 解决方案:纯内存 Push 模型跑赢物理复制
- 放弃让其他在线端去“查”数据库的传统做法。
- 手机端消息先进入 Kafka,由消息处理服务按会话维度分配
Seq并完成落库。 - 后端的
msg_transfer服务消费 Kafka,定位到 PC 端的 WebSocket 长连接,直接将消息从内存推(Push)过去。 - 核心逻辑: 内存与网络的流转速度远快于磁盘 IO 和数据库 Binlog 复制。客户端直接利用 Push 过来的数据渲染上屏,从物理架构上彻底绕开了从库延迟的陷阱。
单调读失效(Monotonic Reads Anomaly)
- 漫游消息凭空消失: 用户断网重连,触发历史消息拉取(Pull)。第一次拉取,网关路由到了延迟极低的从库 A,用户看到了最新的 10 条消息。用户立刻下拉刷新,第二次请求被路由到了卡顿的从库 B,从库 B 还没这 10 条消息。于是,用户屏幕上刚刚还在的 10 条最新聊天记录突然集体消失。
- 解决方案:客户端主导的严格 Seq 游标
- 在 OpenIM 中,拉取漫游消息的“游标控制权”在客户端手里,而不是服务端盲查。
- 客户端本地 SQLite 记录着自己当前看到的最后一条连续消息的
MaxLocalSeq(如 Seq=100)。 - 发起 Pull 请求时,客户端携带极其明确的条件:“只拉取
Seq > 100的增量消息”。 - 核心逻辑: 服务端接收到游标后,会和 Redis 中维护的
ServerMaxSeq对比。如果查到的从库最新数据只有 Seq=95,服务端立刻判定该副本滞后,可以选择等待、报错或强制回源主库。这保证了客户端拉取的数据永远是向前递增的,彻底封杀时光倒流。
前缀/因果一致性失效(Causal Consistency Anomaly)
- 旁观者视角的逻辑错乱: 在百人群聊中,用户 A 问:“去不去吃饭?”,用户 B 看到后秒回:“去”。(A 绝对发生在 B 之前)。然而,A 和 B 的消息并发打入服务端,处理 B 的线程极快,处理 A 的线程卡顿,导致 B 的消息先同步到了部分从库。此时,旁观者 C 刷新群聊,竟然先看到了 B 说“去”,过了几秒才看到 A 问“去不去吃饭”。因果逻辑彻底崩塌。
- 解决方案:Kafka 分区串行化 + 会话内 Seq 发号
- 步骤 1(先入队): 消息以
ConversationID为 Hash Key 投递到 Kafka,确保同一会话的消息进入同一个 Partition。 - 步骤 2(再发号): 消息处理服务按 Partition 顺序消费,并为该会话分配严格递增的
Seq,然后落库。 - 步骤 3(客户端连续性校验): 就算网络抖动导致 Seq=11 的消息先推给旁观者 C,客户端发现本地缺少 Seq=10 时,会先放入重排缓冲区,待 Pull 补齐后再按序展示。
- 核心逻辑: 先利用 Kafka 分区保证同会话处理顺序,再用会话内递增 Seq 做最终顺序锚点,最后由客户端状态机兜底连续性。
- 步骤 1(先入队): 消息以
分布式架构设计:不与底层的物理不确定性(网络抖动、磁盘延迟)死磕,而是通过高层的应用逻辑(Seq、Push/Pull、分区 Hash)来建立确定的秩序
参考资料
- Martin Kleppmann. Designing Data-Intensive Applications. O’Reilly Media, 2017. Chapter 5: Replication, sections “Reading Your Own Writes”, “Monotonic Reads”, “Consistent Prefix Reads”.
- Martin Kleppmann. Designing Data-Intensive Applications. O’Reilly Media, 2017. Chapter 9: Consistency and Consensus.